DevOps Tooling: Foundations
Photo by Mirko Blicke on Unsplash
So you’re moving ahead with the organizational transformation required of DevOps, and it’s time to work on tooling. It’s totally possible to leverage your existing Chef infrastructure to build something that supports a build-test-deploy life-cycle, and perhaps even get developers the fast feedback that they crave. But is that the right approach? Is that enough?
From looking at a bunch of companies, I don’t think it is. I know that’s a difficult thing to hear when you’ve just invested the last few years of your soul into building something epically awesome using traditional orchestration tools, but I urge you to keep an open mind.
The act of abstracting and automating operational activities to the point where developers become self-sufficient with low risk requires revolutionary change. For those still running mutable infrastructure, there’s a simple question: would you give developers access to your Chef or Puppet repos, and root logins to the production servers? If the answer is “yes”, then I want to learn from you. If the answer is “no”, then it’s time for a change.
What do I mean by mutable infrastructure? Long-lived servers and virtual machines where the application and software running on them change over time. The thinking goes that entropy will eventually have its way and changes will diverge: some things will get missed through automation, or servers won’t get refreshed with operating system and library updates. Instead, by using an immutable approach, where every layer of a run-time service gets replaced at once, this whole class of problems just goes away.
But you can’t just start there.
Often times, we think that DevOps tooling is about continuous integration and deployment, and that it’s a straight-forward process to add it on top of existing infrastructure.
Unfortunately, reality is far more complex.
Relying on legacy infrastructure will cause some huge problems. These environments have typically been thought about with classic data center paradigms in mind rather than the facilities available in the modern cloud native world. Furthermore, services and infrastructure were typically built organically and piecemeal which means that there will be special cases and differences each time. You’re also likely to find abandoned systems. It’s totally normal and expected, but the world has changed, and we can do better. Cattle not Cats.
Over the past four years (and in conjunction with others, of course) I’ve used a from-the-ground-up list of infrastructure layers required to support DevOps culture. It will continue to evolve as both technology and my level of experience develop.
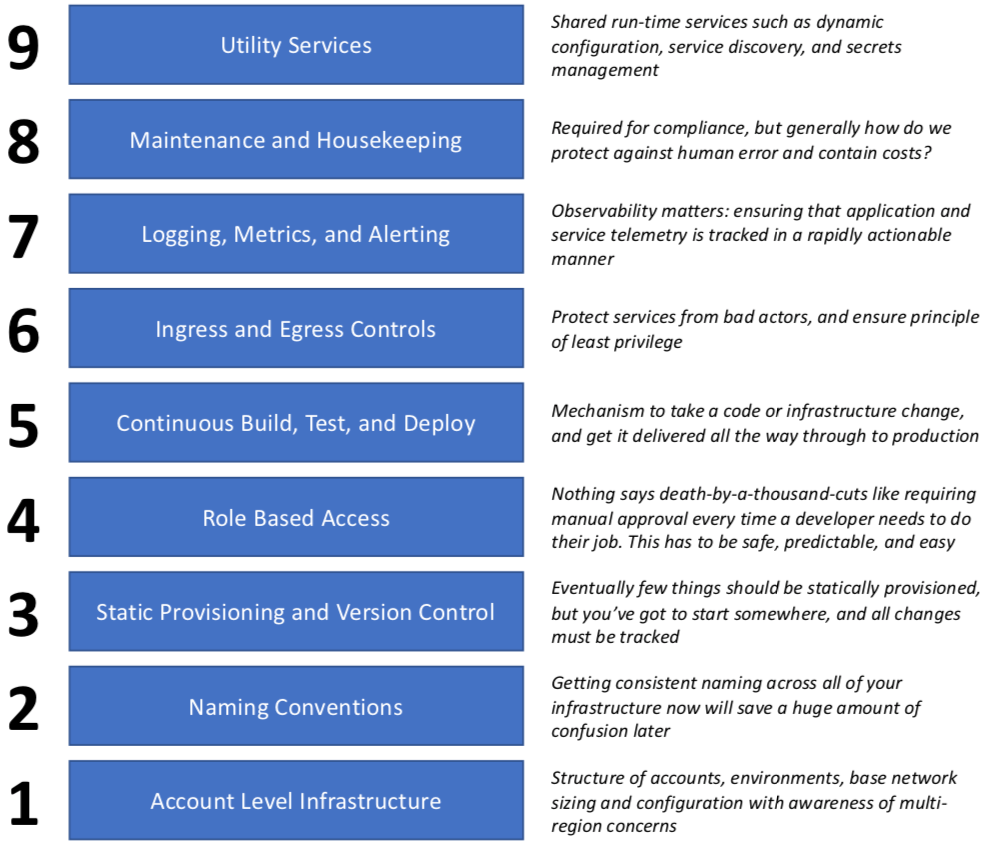
Each of these items are predicated on the layers below (although sometimes there’s a chicken-and-egg thing going on with cross dependencies), and each one of these items requires its own article or perhaps even series.
Whether you chose this specific model or a variation that works better for you, decompose the layers in advance, think about how each layer enables the next, then celebrate, retrospect, and evolve after each.
In any case, though, hopefully you see that doing this correctly is not trivial, and some significant investment in time is required. Oftentimes it’s better to think about this in the context of a longer term/higher impact company transformation, rather than investing in the work for the benefit of a single team.
You may even want to evolve your definition of done as you go…

Join our community Slack and read our weekly Faun topics ⬇

If this post was helpful, please click the clap 👏 button below a few times to show your support for the author! ⬇
This article originally appeared on Medium.