Regulatory Compliance, DevOps, and the Cloud
Photo by Helloquence on Unsplash
From an infrastructure perspective, it’s common to feel the need to invest a lot of time and effort in ensuring that we’re compliant with regulations, and we expect it to be hard. But that’s okay, right? After all, the act of putting a lot of effort into the process just shows that we’re taking things seriously.
But I think that’s a fallacy, and it doesn’t need to be so hard. Compliance should never slow development effort down or restrict delivery of incremental business value.
It was the spring of 2016. We were just coming down from the high of replacing Netflix Asgard with Spinnaker, and adoption was going well.
My SVP asked me what I knew about PCI, and I replied honestly: nothing. He suggested I should figure it out, because we were about to start running credit card transactions through our systems, and — given of the nature of the business — we’d just reached PCI DSS Level One, meaning that the company processes over six million credit card transactions each year, and is subject to the most rigorous level of oversight.
Then we talked with our compliance folks, and realized that we also needed to concern ourselves with Sarbanes-Oxley (SOX) since our future plans included moving all of our back-end business systems into the cloud.
I was super worried.
But then looking at the standards for these two, it turns out that we were already in good shape, since we’d built in security as a first class citizen when designing our infrastructure.
This is really important: design things well, and compliance is easy because you’re following best practices; design things poorly where you have to bolt-on layers of complexity to support regulatory concerns, and you’ll just reduce the ability for the company to deliver incremental business value.
That Thing You Have. It’s Probably Too Complex
It’s a pretty judgey statement, isn’t it? But bear with me, I want to mention something that I’ve seen at a couple of places.
As developers at traditional software shops, we’re often isolated from the pains of regulatory standards and it’s not always obvious what goes on from the operations side. For the ops folks though, audit time can get pretty scary and even something to dread.
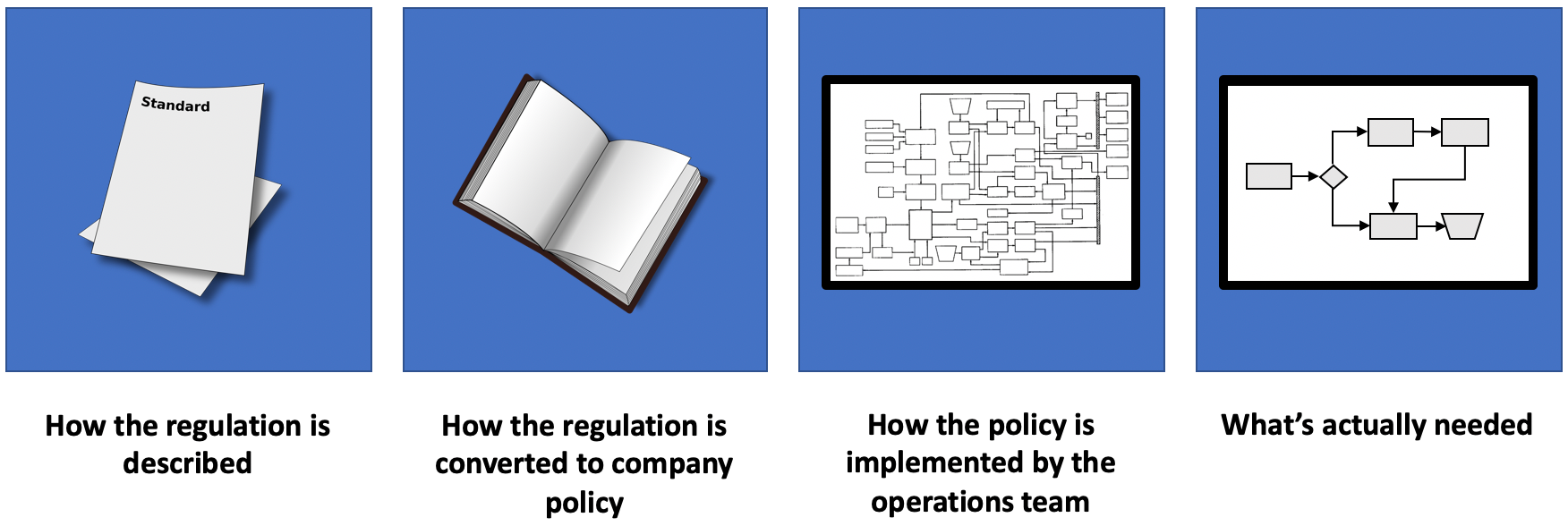
Regulations are typically published as either delegated legislation, or industry self-regulation and are created in order to support fairness and safety, whilst minimizing opportunity for adverse business impact;
The company may have a compliance team that develops a set of corporate policies based upon those regulatory requirements. These policies morph over time as things are learned about breaches, changes to the law, and even based on whims of personality;
The operations team will likely have interpreted the rules from the compliance team, and come up with their own implementation based on what they understand, and what they think constitute the best operational practices;
In turn, the operations team will likely be influenced by other folks as trauma occurs, and they seek to incrementally plug individual operational areas of risk, and perhaps even seemingly unrelated events such as the adoption of an interpretation of Agile practices. Typically, little or no process or systems refactoring happens during this time.
The net is a set of rules that — although might not actually require sacrificing chickens on the third Thursday of the month — are probably nearly as arcane, inaccessible, and one of the reasons why developers can’t deliver changes to production rapidly.

But perhaps it’s even worse than that.
At one company, we had a “pen” of PCI-related servers in the data center, but as the relationship between payment systems and their peers became increasingly fuzzy, more and more systems were pulled into scope. When I joined, about 70% of our production systems were part of the PCI audit.
If you haven’t thought about designing services with loose coupling, then chances are that many adjacent systems are subject to the gravitational pull of the compliance black hole, and will subsequently also require auditing.
The increase of scope means that the overhead of threat assessment and audit becomes huge, potentially taking weeks or months of effort.
I think the net is that — counter intuitively — innovating layers of “stuff” isn’t always good… particularly in the context of compliance. The idea of adding additional layers of complexity to manage the complexity a la There Was an Old Lady Who Swallowed a Fly, eventually getting to the point where you have so much going on that you have to build AI infrastructure to analyze risk seems horrible to me.
Okay, so… What‘s Better?
Look at that fourth box of “what’s actually needed”. How can we accomplish such a thing?
Question Everything
If you’re a veteran of software and operations, then you can usually see a smarter way of doing things.
Just because the company has policies, it doesn’t make them correct or justified. You want to do the best by your company, right? Why wouldn’t you think critically about the systems that are running and ask why a particular process or policy has to be brittle, complex, or slow? Is it the best it can be?
Protect Scope Fiercely
Along the way, you’ll meet people who have a hard time believing that anything less could be fit for purpose. People who are passionate about what they do and are perhaps fearful of change. Work with them as closely and collaboratively as you can. This will take time and effort but avoid being bullied into doing something that you know is wrong.
Strive for Simple Solutions
Look back to the regulations and solve using first principles. I’ve seen a two-paragraph regulation get blown up into an eighty-page company standard. Nobody is going to read eighty pages of text, let alone consistently remember what they have to do day-in-day-out.
Audits can be a deeply mechanical and complex thing if you’re not careful. At one company, there was a huge slog to manually fill out a 300+ line spreadsheet of in-scope servers answering various questions. Even worse… that process had to be repeated several times.
Having a bunch of spreadsheets to track progress of an audit is an indicator that something is wrong. What can be done to eliminate all of that manual tracking?
Similarly, from a day-to-day operational perspective, requiring key individuals to manually review application or infrastructure changes, grant temporary credentials, or watch for root login alerts, then it’s time to re-think.
Consider also driving homogeneity and a policy of cattle not cats… the fewer special cases in design and implementation decisions, the less learning there will be for auditors between services as they become increasingly comfortable with how things operate, and the fewer questions they will need to ask.
Eliminate Silos
This is, of course, a founding principle of DevOps. Anything where one individual (or team) relies on another individual (or team) to do something is bad.
Although we can’t totally eliminate this for concerns such as separation of duties, it turns out that there are degrees of silos. For example, consider that having someone on your team who is tightly aligned with the stories on your sprint review and can sign off on your changes no later than next stand up will have two advantages over someone in another department fulfilling the same role:
Their objectives are tightly aligned with your objectives, and there will likely be less conflict in priorities. This means that change will likely be effected more rapidly;
They understand context of the change, since it’s aligned with the team’s goals. They are also likely appropriately technically skilled and will be able to understand the changes and their implications with much greater degree of precision than someone in a separate change control or change management group.
For all but the largest of companies, a dedicated (read “full time”) change management group is likely small and won’t get the benefits of economies of scale. This means that they will struggle in the event of absences or employee turnover. For ad-hoc (or “part-time”) change control that meet at some cadence, then changes may be gated by that cadence, and certainly the full-time concerns of those individuals will likely drive their priorities.
Minimize Attack Surface and Consider Contingency
Always spend a little time thinking “what if…?” and acting appropriately, perhaps even running some Red Team scenarios. For example:
Are there adequate protections in place to minimize opportunity for illicit access?
Should there be a breach, is there sufficient logging in place to track the source and extent of the compromise?
In the event of a systems failure, is there resilience in place to carry the load?
In the event of a systemic failure, is there ability to recover with minimal loss?
Simplify and Segregate: Eliminate Complexity
Honestly, most auditors don’t wake up every morning rubbing their hands with glee at the prospect of taking a company down or making someone cry.
Their job is to certify to the best of their ability that the stuff they are looking at is safe and fit for purpose. The more complex the infrastructure that they have to examine, the harder time they will have in making a determination and the more questions they will have to ask along the way. Everything you can do to isolate and eliminate complexity, the easier their task will be and the faster you can get back to your day job. Rube Goldberg machines are bad.
I once came across a micro-service that was part of billing life-cycle, and so subject to SOX controls. Which is to be expected, of course. The rub though was that — for some reason — this micro-service also included weather service APIs. Because of this, more code, more infrastructure, and more changes came under scrutiny at audit time.
Empower
Change management and change control are power-based structures which imply silos. Organizations institute workflow like this because — over time and accumulated error — there develops a lack of trust in the software development community.
A better question is to ask how can we empower developers to make better decisions for themselves, without needing hand-holding or control?
Automate Everything
Boil the problem space down to the essentials, and then automate what’s left.
Nothing is perfect, but automated systems tend to be a lot more consistent, faster, and reliable than when a human is relied on to complete a task. As long as there is high confidence in the integrity of the automation, then your story at time of audit becomes trivial.
One real world scenario had the ops team manually sort through all the tickets on their Jira board to get a list of changes on a particular service for the auditors, which literally took hours. As part of continuous delivery, we added audit steps to post updates to a change database and ServiceNow, so that generating a list of changes just took a couple of minutes.
Okay, so What’s the Best We Can do?
The best we can do is to make it somebody else’s problem.
There are companies who have regulation and compliance as part of their core business model and provide this as part of their service. Cloud PaaS vendors like AWS and Azure fit into this category, since they manage data centers with physical access controls, power redundancy, and so on.
At a higher level for PCI, take yourself out of the business entirely. For most companies, processing credit card transactions is not a core competency. Rather than handle card numbers, it’s simpler to use a tokenizing solution such as those from Braintree Payments and Stripe for software or Datacap for embedded systems, for example. Because you only handle a transaction token and don’t see any personal information, you’re exempt from the regulation.
Summary

Why is this all important?
It’s common for those involved to fear audits and the questions that auditors raise. I don’t think it has to be that way, though. How do you get to the point where an audit is a celebration, and we work in partnership with auditors as they help us on the path to be the best that we can be?
My first experience with external auditors from Deloitte was being dumped into a room with no warning or prep time. Obviously, that’s less than ideal.
I went into that meeting stating “this is going to be fun”, for which the response was a set of stern faces and grumbles of “it’s not that sort of audit”. But we quickly developed a sense of rapport as they realized that I wanted to learn all they had to teach, and in turn introduce them to DevOps principles.
Our ideal end state should be for auditors to either confirm what we already know about how secure our systems are (because we’ve thought about this stuff from the ground up) or show us how to improve. Improving is good… again, we want to be the best we can, right?
As awareness of regulatory concerns grows with developers, and an understanding that auditors will be interacting with them directly, it’s likely that services will also start to get designed better from their foundations.
I know that this can all sound naive for organizations which are aggressively pursuing business goals, but what’s the net cost and net risk to the company compounded over a year or two by avoiding this efficiency? How much people time is being thrown away? What could those people accomplish if they weren’t bogged down in details?
This was a huge learning journey for us, and I’ll talk separately about the specifics of some of the tricks we applied, but the first step is to begin believing that life can be better.
This article originally appeared on Medium.