Why They’re Bad: Silos, Heroes, and Yaks
 Original art by Christina St.John Studios
Original art by Christina St.John Studios
During the course of writing the Beginning DevOps series, I mentioned silos. Maybe the problem with silos is obvious, but maybe it’s not. So I thought I’d talk about why silos are bad, and while I’m at it… what’s wrong with heroes, and what is that yak doing here?
Silos
Newly formed companies are typically staffed by a few people who wear many hats. Because there are so few people to do the work, everyone has to chip in to get the job done whether they’re an expert or not.
As a company grows, so does demand for specific skills and it’s common to formalize functional areas of specialization such as Marketing, Engineering, Finance, Facilities, Human Resources, and so on. It’s normal.
It’s important to limit how far specialization goes within a particular functional area though: the more distinct hand-off points there are in completing a particular deliverable, the longer it’s going to take, and the greater the chance for error. The more specialization and hand-offs there are, the more silos there are.
Consider this simple workflow:
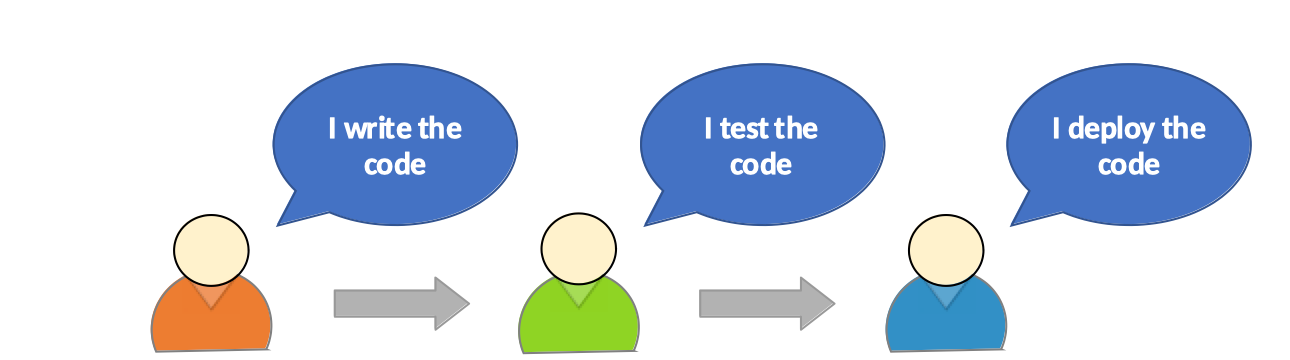
In practice there are often more steps than this, but it illustrates the point.
Think about the various stages there are involved in communication between the three individuals. Along the way, you’ll see delays introduced because it’ll take time for the next person in the chain to get around to taking a look at the work that needs to be done, then understanding requirements, and finally — when the work is complete — they’ll need to document their work and hand off ready for the next person in the chain to continue the task. Excepting a subset of boxes for those at the beginning and end of the chain, each individual has these overheads:
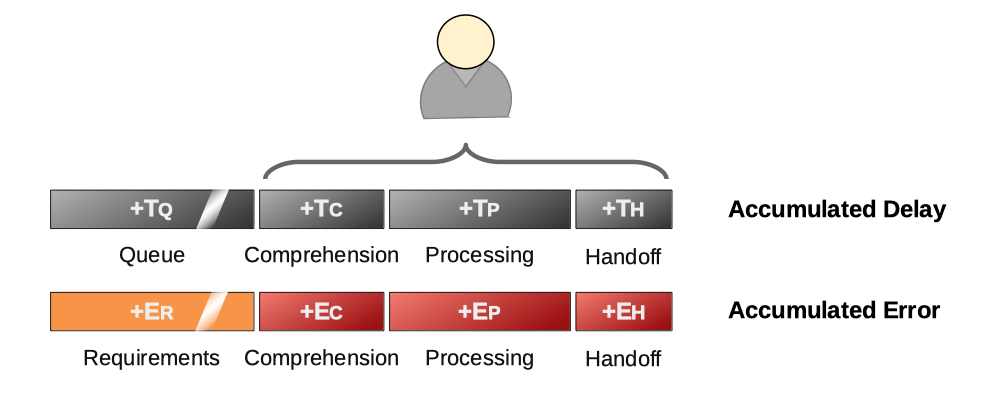
As well as adding delay, each of these four stages has a risk of incurring errors: the requirements could change while the task is in the queue, and — because a human is involved — there is risk of (1) misunderstanding what was needed; (2) making mistakes when working, or even introduce errors while handing off to the next person.
Using automation to eliminate a lot of these hand-off points and empower developers to do everything for themselves swiftly and reliably meant that we gained at least a 5x increase in deployment cadence, and trivialized the number of change-related outages that we suffered.
The important truth of the matter is that the fewer individuals you have in getting something done, the faster and more reliably you’ll do it, especially when simplification and automation is introduced.
Heroes
Heroes are bad.
Obviously, you want smart capable people around who understand systems and are capable of troubleshooting when things go wrong.
It’s not about that.
I’ve seen situations where operations teams were on the front line for all operational issues, even though they weren’t involved in instituting changes and weren’t experts with that particular application code. The first they hear is that something has gone horribly wrong, and the company is losing money by the minute.
After some indeterminate amount of time, everything will be running once more and there will be relief and celebration.
Fundamentally, the feedback loop is broken if your company segregates the role of production operations (and “first line of defense”) from software development, and it’s that operations team that gets the emergency call.
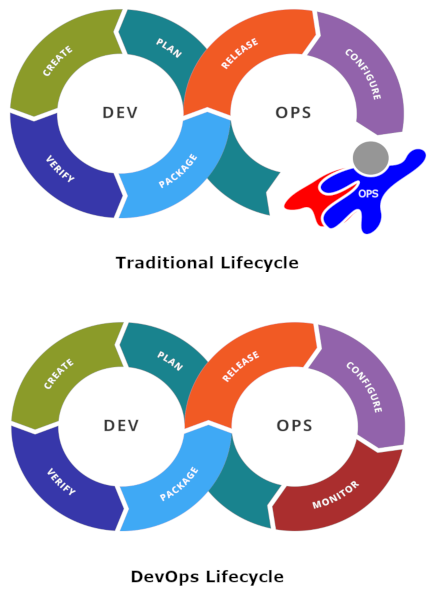 Sources: Wikipedia, and Wikimedia Commons (modified)
Sources: Wikipedia, and Wikimedia Commons (modified)
The first diagram here shows one aspect of traditional life-cycle where an operational team intercepts production outages and handles more minor operational issues. You could argue that this is great because you’re allowing your development teams time to focus on writing features, which in turn should help the business grow faster.
The truth of the matter, though, is that because the feedback loop from production monitoring to planning is broken, development teams are insulated from critical information required in order to best prioritize their work. Over time, this lack of feedback causes more and more technical debt to accrue in the software, and an ever-increasing burden on operations. If you’re not careful, it’ll reach a point where it becomes incredibly hard to recover from.
Conversely, the second diagram shows a closed feedback cycle, which is great: developers are able to address anomalies with the correct sense of urgency. With this model, the conversation changes from a celebration of the individuals who recovered from disaster to how do we improve our systems?
This alternative DevOps approach means that developers will get fast feedback on how their code is performing, and they can address any imperfections quickly because they have great insight into how their code works.
So I urge you: coach your developers to ensure that they are designing observable systems that have sufficient monitoring and alarming in place to enable them to respond directly and quickly as soon as something starts to go wrong. With this approach, you’ll incur fewer outages of significance, you’ll end up delivering features at higher cadence, and you won’t need heroes.
Yak Shaving
People often look at me in a weird way when I talk about yak shaving. Which is understandable: it’s pretty obscure. It’s not quite the same thing, but it shares many traits with the term toil that is used in site reliability engineering.
The net of it is that you’ve got this one simple task that needs to be performed, but in order to accomplish that task you have to take care of a bunch of other things first, and end up finding yourself doing something obscenely irrelevant.
In part, yak shaving can be a symptom of silos: I’ve seen cases where a team that is responsible for a system doesn’t have time to make a change required for another team, and so the second team builds an entirely new layer of code on top of that first system, since the cost of waiting for the right change becomes unbearable. Similarly, I’ve seen cases where layers of code are added to an application because nobody is sure how that code operates and is afraid of breaking it.
As another example, it should be easy and of low cognitive load to push your change to production. In practice, however, it’s common to develop a volume of ritual and complexity that make production changes burdensome. Dilbert Comic Strip on 2008-05-11 | Dilbert by Scott Adams The Official Dilbert Website featuring Scott Adams Dilbert strips, animation, mashups and more starring Dilbert…dilbert.com
When changes to production become burdensome, there’s a temptation to cluster several-to-many changes together for deployment with the view that this is more efficient. Unfortunately, rather than increasing efficiency, this makes it harder to determine which one of a batch of changes caused a production outage, and the time required to isolate what caused the outage will grow exponentially.
I’ve seen changes take months to find their way into a production deployment. I can’t usually remember what I coded a couple of weeks ago, let alone months. This loose feedback cycle makes troubleshooting hard, and will inevitably cause extended downtime.
In the short term, it’s important to start to recognize which bits of your ritual involve shaving yaks. In the medium term, think about what you can do to simplify your workflow, whether it’s fixing broken systems or processes, automating repetitive tasks, or eliminating unnecessary complexity.
Putting it all Together
I didn’t see the terms heroes, silos, and yak shaving in a book (or a tee shirt), I experienced it firsthand coming into several organizations. When you get to the other side of the transition, you won’t want to go back.
Generally speaking, although organizations want to do the right thing, there is a natural tendency to add process and complexity in order to restrict opportunity for repeat mistakes, divide work to provide niches for high performers with a view to improving scalability, and drive top-down control without the same level of understanding as that available to those “on the ground”.
Unfortunately, these naive control-based approaches that are intended to improve safety and efficiency will have the reverse effect. It’s easy to miss the impact of a change without a sufficient closed feedback cycle in place to empirically measure the effect of change.
The net of this is that it’s important to coach and instill a sense of ownership into those able to make the best empirical decisions based on measurement, driving homogeneity, and minimizing overheads. This in turn will help drive faster and more effective feedback cycles.
Then again, looking at the headline image for this post, egos and blame are another thing all together…

Join our community Slack and read our weekly Faun topics ⬇

If this post was helpful, please click the clap 👏 button below a few times to show your support for the author! ⬇
This article originally appeared on Medium.