DevOps Tooling: Not Your Granddaddy’s Definition of Done
Photo by rawpixel on Unsplash
As you work through your tooling implementation layer-by-layer, there’s plenty of opportunity to overlook critical aspects that will come back and bite you later.
Just as with any project related work, I think it’s important to have a definition of done beyond what’s required of a basic technical specification. Success isn’t just about how we can show that this thing works in a happy path world, but that we’ve thought ahead to longer term maintainability.
After a lot of trial, error, and retrospectives, we found that it was good to have a ritual check list on hand for both the design phase, during implementation, and as a sanity-check when the work is done. There’s a good chance that you’ll save yourself a lot of pain down the road by consistently following this approach.
Perhaps you’ll end up with your own variation of this list, but here’s the one that we evolved over time that you might find useful. Call it CROMSIS if you like.

Consumable
Will a consumer with little or no operations background be able use it without having to ask questions, make horrific mistakes, or need to be pushed along in order to begin using a new or updated system?
We are all creatures of habit and tend to avoid investment in activities that require high cognitive load with potentially little visible payback, particularly relative to all of those regular activities which demand our time. So the ability for new consumers to on-board in a simple, self-service manner is key.
Let’s make it as easy as possible to adopt (which is most fundamental), and then make sure that there are resources available to help should something come up. Although it’s unlikely that you’d need all of these, some examples might include:
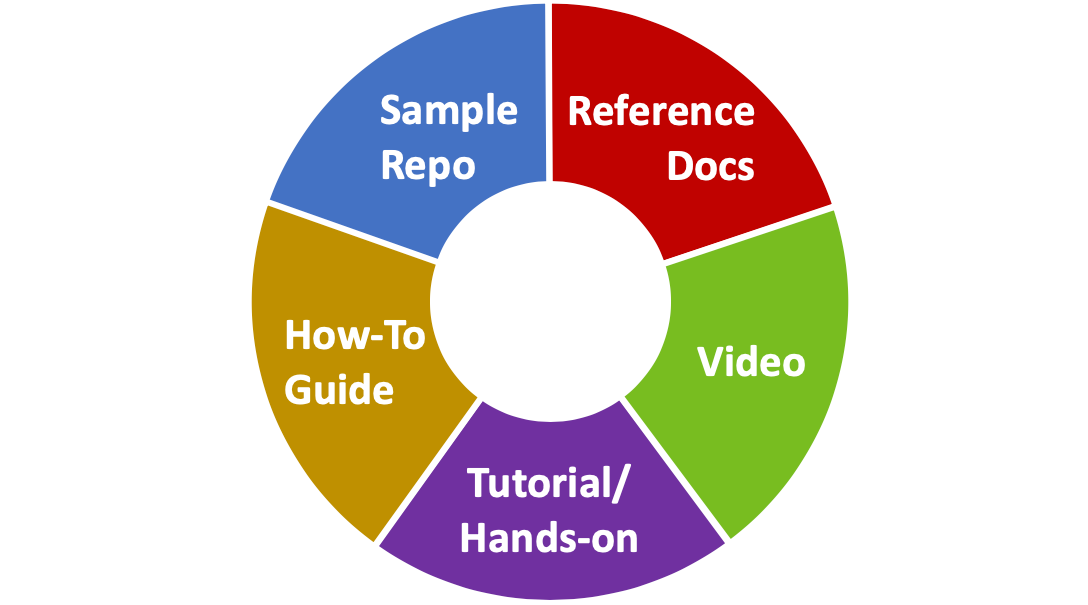
Each of these media have their own advantages and disadvantages, and are very much dependent on both the audience and the subject matter.
A fairly advanced approach is to gamify the adoption of new technology and services, which adds incentive and can make the process more fun.
Reliable
There’s a line to be drawn ahead of over-engineering a solution, yet the implementation has to be adequate: don’t add five layers of redundancy where one will do.
Have all the likely failure scenarios been considered? What happens when load increases to unexpected levels? What happens if a server instance, availability zone, or network link fails?
Over time, and as the team’s level of sophistication develops, you can also consider chaos engineering as a way of sanity checking changes.
Observable
It doesn’t matter how hard you try, something will go wrong eventually.
I’ve talked somewhat humorously about the three modes of failure discovery with DevOps tooling teams: the best case is we find it and fix it before anyone notices, next worst is that one of our customers finds it, and worst case is that the boss finds it. You might legitimately argue those last two, but the first is always preferred.
Is there the right level of monitoring and alarming in place? Will alerts make their way through to the right person in a timely manner?
Maintainable
Is this implementation lean and as simple as it can be, free of unnecessary complexity? The more complexity there is:
The more things there are that can fail;
The more steps there are likely to be when troubleshooting;
The larger the attack surface;
The more work has to be done in order to update, upgrade, or enhance
Does it rely on as few custom components as possible?
Is there sufficient documentation on hand that a new member of the team can get up to speed quickly?
Can software components and configuration be upgraded with ease, and preferably at any time during the business day with little or no risk to production services?
Secure
Is this built with security as a first class citizen? Are you sure? Change your posture and spend a little time thinking like a Red Team: you might be surprised at what you learn when you think like the enemy.
Also consider this from the perspective of all roles that could potentially interact with your system, such as:
Individuals with varying levels of legitimate user to administration access who should only be able to perform actions within their permitted domain;
Bad actors who are looking for even the smallest flaw that can be leveraged for privilege escalation;
Auditors who need access to be confident that sufficient controls are in place
That being said, a degree of common sense should be applied: too much security can be obstructive and slow things down. That’s not DevOps.
Isolated
There is some awareness of coupling as a measure of reliability from a software point of view, but it’s often overlooked from an infrastructure perspective.
As much as you can, ensure that the implementation relies on as few things as possible, but — of course — don’t rebuild or copy a component that’s used elsewhere just to reduce coupling.
Scalable
I talked about handling increased server load earlier, but what about when the number of developers using the tooling grows from ten, to a hundred, to a thousand users or more? Is there a sense of community around these things being built so that teams can become self-sufficient in on-boarding new hires, and solving common problems within their own team?
Summary
Ultimately, this is about maintaining measures of success, and holding ourselves accountable.
Think about the constraints involved when you have a small team of professionals responsible for building and continuously evolving the tooling that developers will consume as they learn to deliver reliable software at ever-increasing velocity.
Taking it one step further, this is not just about how the tooling team delivers services: there’s a lot of utility in applying this checklist for software developers who are truly DevOps and are building modern services.
The big implication from a tooling perspective, though, is that you can’t compromise on quality or performance of the solutions you deliver. If you do, then you’ll very quickly become bogged down in details and turn into an operations team that frustrates delivery of software at speed.
With thanks to Vida Popovic and Joel Vasallo.

Join our community Slack and read our weekly Faun topics ⬇

If this post was helpful, please click the clap 👏 button below a few times to show your support for the author! ⬇
This article originally appeared on Medium.